企业大数据开源平台,从部署迈出第一步
最近应项目公司需求,我们需要为其构建一个大数据平台。开源的Hadoop生态应用 由于没有技术服务支持,公司不采用此种方案进行构建。因此我们选择采购具有技术支持的 第三方大数据平台,当然这些公司的平台也完全基于 Hadoop, 只不过他们有着一帮技术团队,可以为自己平台出现的问题提供技术服务。
第三方平台目前我们所接触了解的有四家:
而由于 Cloudera 提供了开源免费版本的产品,因此这篇博客主要对 Cloudera 公司产品的部署过程进行记录。
简要介绍
- Cloudera: Cloudera 公司目前是世界上最大的大数据平台提供商,其总部位于美国,且已经上市,2014进入中国市场,Hadoop 创始人 Doug Cutting 目前也就职于Cloudera,担任首席架构师,其内部有很多开源项目的 Committer,相比其他公司,其技术水平有着绝对的优势。
- CDH: Cloudera 公司目前主要的产品是 CDH ( Cloudera’s Distribution including Apache Hadoop ),是对 Hadoop 生态( hadoop + hive, hbase, flume, impala 等等)的一种封装融合,该产品是 完全免费下载和安装 的,其盈利方式是技术支持服务。
- Cloudera Manager: 由于大数据平台本身就是分布式,CDH 自然也不例外,为了便于用户快捷安装,Cloudera 公司提供了 Cloudera Manager 工具,可让用户在可视化的页面上组织自己的集群。
- 部署方式:首先,Cloudera 公司提供了产品的尝鲜版本,主要提供了Virtual Box、VMWare、KVM、Docker Image 等虚拟镜像,为了体验产品的用户可以尝试。此外,Cloudera 提供正式版本的安装说明,下面就按照正式版本正式生产环境进行安装部署。
环境准备
目前,Cloudera 最新版为 CDH5.13,因此本教程基于 CDH5.13 安装
硬件准备
搭建一个包含四个节点的集群,1 个 master, 3 个 slave, Host IP 对应关系如下:
1 | 1. 192.168.1.100 master |
各个主机的物理配置如下,master 至少 16G 内存,slave [ 1-3 ]至少 4G 内存:
1 | master: CPU 16 核,32GB 内存,500G SSD |
软件准备
系统环境为Ubuntu16.04-Server版本,我们需要提前下好如下数据包:
- Cloudera Manager 安装包,约 750MB;
- CDH 离线资源包,约 1.9GB;
- CDH 离线包验证文件,约 41B;
- CDH 离线包内的组件描述文件,约 74KB;
- JDK8 安装包,约 180MB;
其下载好的对应文件名如下:
- cloudera-manager-xenial-cm5.13.0_amd64.tar.gz
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel.sha
- manifest.json
- jdk-8u121-linux-x64.tar.gz
下载时需要确定自己系统的版本名称,Ubuntu 16.04 的对应的版本名称为 xenial,下面为对应文件的下载地址:
- Cloudera Manager: Cloudera 官网地址
- CDH 资源包、CDH 校验文件、manifest.json: Cloudera 官网地址
- JDK: Oracle 官网地址 或者 个人仓库地址
正式部署环境配置
正式的环境安装,以下操作均以 root 身份执行
基本信息修改
主要修改 Hostname 以及 Hosts 配置。修改 Hostname 是为了我们集群好查看和管理各个结点,而修改 Hosts 则是为了我们不用每次输入命令时都输入对方主机的 IP,我们直接输入 Hosts 中 IP 对应的名称即可。
修改hostname: 所有节点,将各个主机名设置为对应的名称: master, slave1, slave2, slave3,master 主机修改为 master, slave[1-3] 则修改为 slave1,slave2,slave3, 修改命令如下:
1 | # 所有节点 |
Hosts配置:主要修改 /etc/hosts 文件,修改命令如下:
1 | # 所有节点 |
免密登录
安装过程全部自动化,因此需要让 master 主机到所有其他 slave 主机可以免密登录。
由于是刚装的系统,Ubuntu 默认没有开启 root 远程登录的权限,所以需要先配置所有主机可 root 远程 ssh 登录,主要编辑配置文件 /etc/ssh/sshd_config,修改命令如下:
1 | # 所有节点 |
其次,要配置 slave 信任 master 主机。首先在 master 节点上生成 ssh 公钥私钥,执行 ssh-keygen -t rsa 一直回车,会生成在用户目录下的 .ssh 文件夹里,里面存放了公钥和私钥。然后再将生成的公钥添加到 master 和 slave[1-3] 主机的信任授权列表里,命令如下:
1 | # master节点上 |
最后,测试 master 免密登录各个节点是否成功,使用 ssh [hostname],若回车后自动登录,则成功,操作命令如下:
1 | # master节点 |
配置JDK环境
首先,解压 JDK 压缩包
1 | # 所有节点 |
然后,配置 JAVA_HOME 和 PATH 环境变量
1 | # 所有节点 |
最后,测试 Java 是否安装成功,输入 java -version ,显示 Java 版本即可。
安装MySQL
这个在 master 节点安装即可
1 | # master节点 |
正式部署 – 安装 Manager
安装之前需要将必要的软件上传到 master 节点上,文件包含:
- cloudera-manager-xenial-cm5.13.0_amd64.tar.gz,
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel,
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel.sha,
- manifest.json
解压文件
解压 cloudera-manager-xxx.tar.gz 文件到 /opt
1 | # master节点 |
连接 MySQL
安装过程中 Cloudera Manager 需要用到 mysql 服务,所以这里需要先提供好 mysql 资源。
首先,安装 mysql-connector-java 包,并链接到 CM 库:
1 | # 所有节点安装库 |
然后,再创建 cm5 的数据库:
1 | # master节点 |
配置Agent
这个 Agent 实际上就是安装代理,分布式的每台机器安装过程中都会产生这个进程,那这些 Agent 由谁来操控,通常是由 master 节点进行管理操作,所以要先将配置文件的管理这指向 master.
首先,修改配置文件的 server, 指向 master
1 | # master节点 |
然后,同步 Agent 到 slave[1-3] 节点
1 | # master节点上 |
最后,为所有节点创建 cloudera-scm 用户
1 | # 所有节点 |
配置 Parcels
要安装 CDH5, 我们需要配置 Parcels,这个是 Cloudera 给的安装包的镜像仓库地址,但是国内访问速度很慢,因此我们不使用在线安装,而是通过已经下载的 parcel 包,将其放置在下载镜像的目录,表示 parcel 包已经下载好了,这样就不会再联网下载了。
首先,在 master 节点,用下面命令创建文件夹
1 | # master 节点 |
然后,传入三个文件:
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel,
- CDH-5.13.0-1.cdh5.13.0.p0.29-xenial.parcel.sha,
- manifest.json
启动 Server 和 Agent
在 master 节点启动 Server 进程
1 | # master 节点 |
在所有节点启动 Agent 进程
1 | cd /opt/cm-5.13.0/etc/init.d |
这里假如大家有错误,可以查看对应进程的日志:
Server 进程 log 日志文件:
/opt/cm-5.13.0/log/cloudera-scm-server/cloudera-scm-server.log
Agent 进程 log 日志文件:
/opt/cm-5.13.0/log/cloudera-scm-agent/cloudera-scm-agent.log,
如果没有 .log 文件,可以试试 .out 文件
正式部署–可视化集群配置
等待 Cloudera Manager Server 和 Agent 启动完毕后,就可以进行 CDH5 的可视化界面安装了,在浏览器打开 http://master:7180, 注意,如果这是在 master, slave[1-3] 主机上时可以直接在浏览器里输入这个 url, 但如果 不在 master 和 slave[1-3] 节点上访问此 url,则需要修改主机的 hosts 文件,修改方法见 正式部署环境配置 中的 hosts 配置。
登录
默认用户名和密码都是:admin

同意条款
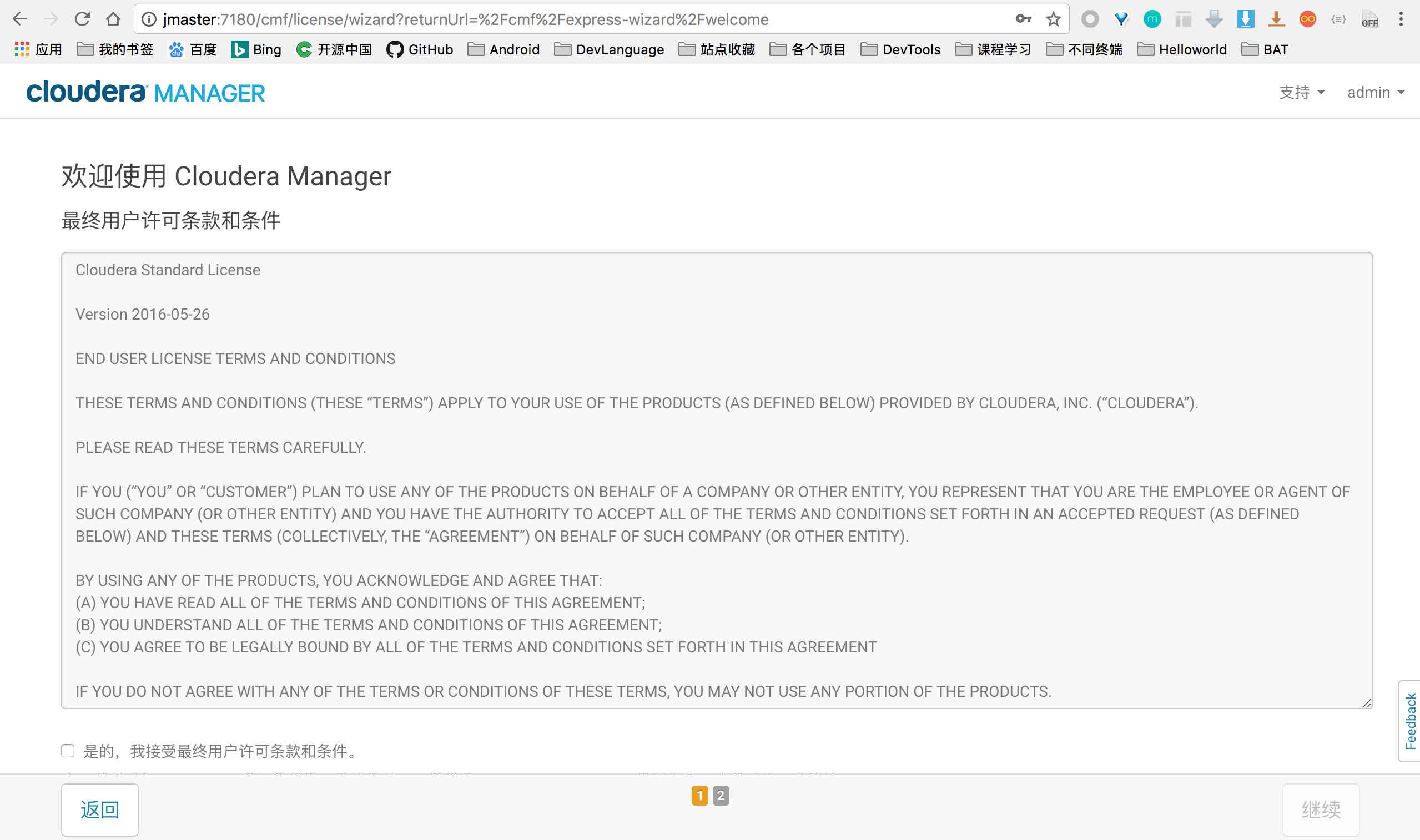
选择版本
选择中间的试用版本,肯定要体验最全的功能
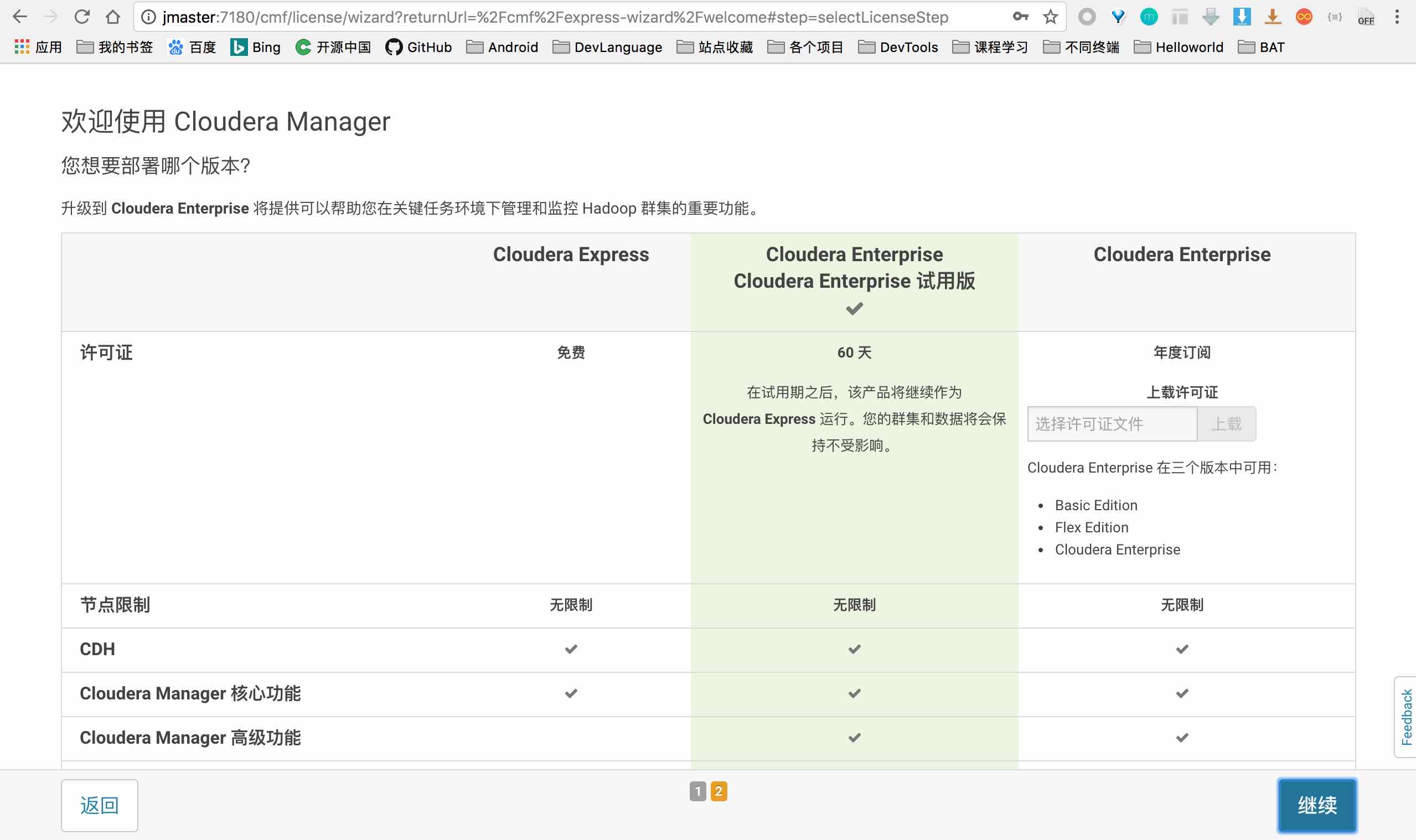
选择集群机器
这里只显示启动了Agent进程的主机
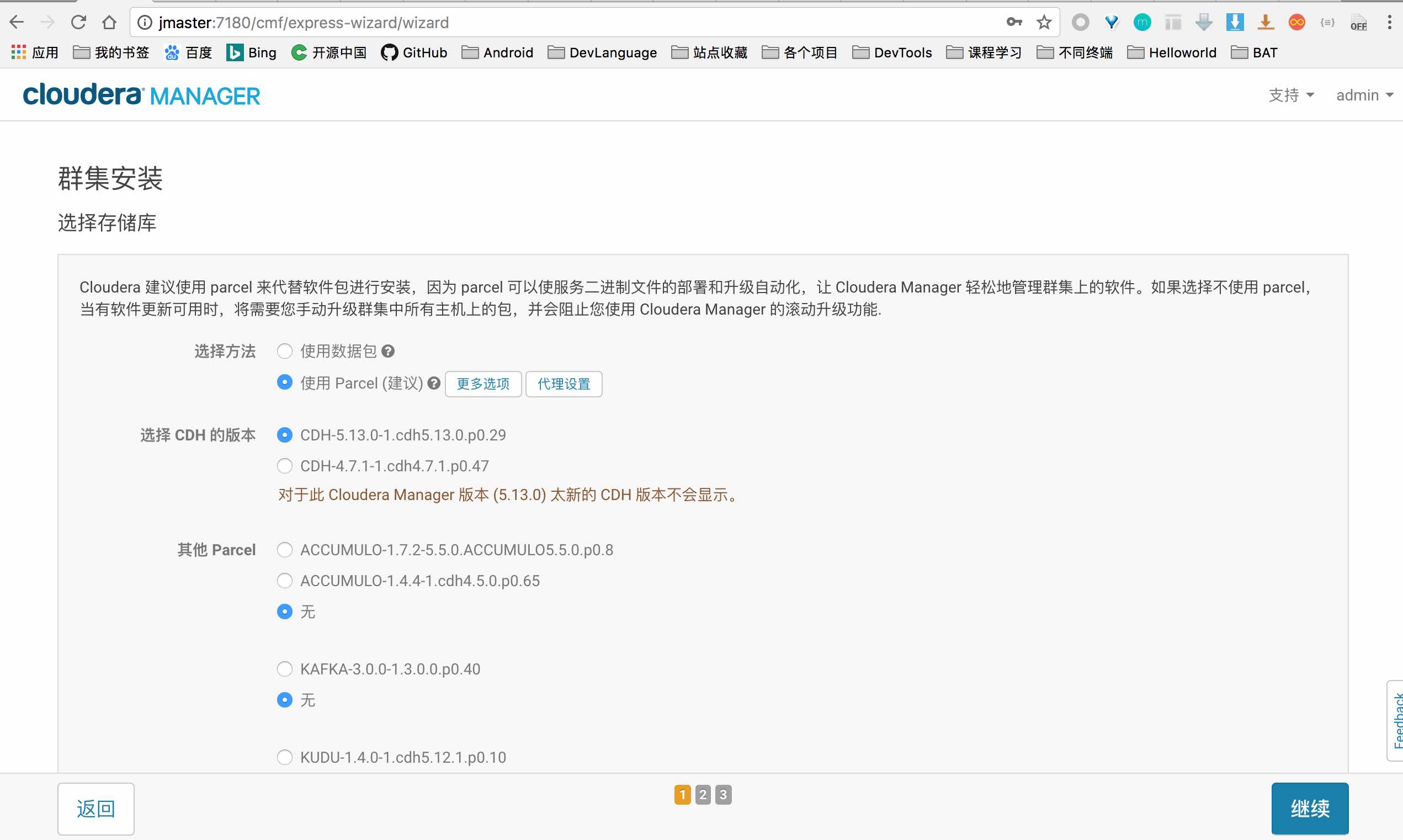
选择集群安装方式
这里选择 Parcel, 我们之前已经把离线包下载好并放在了 master 的仓库目录下,因此这里直接显示了我们已经下载的 CDH5
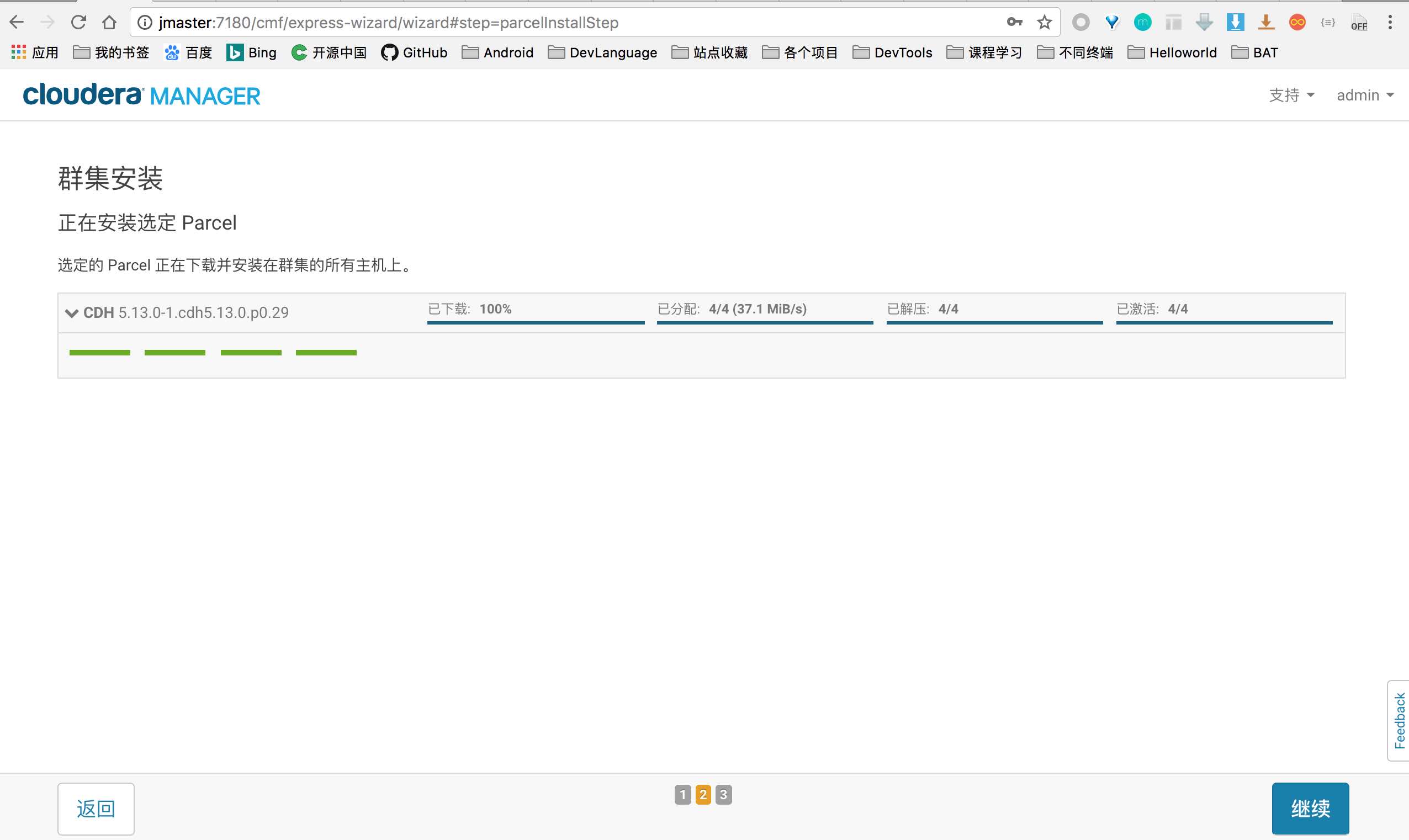
分发 Parcel 包到各个结点
这里自动由 master 将 CDH 包分发到 slave[1-3]
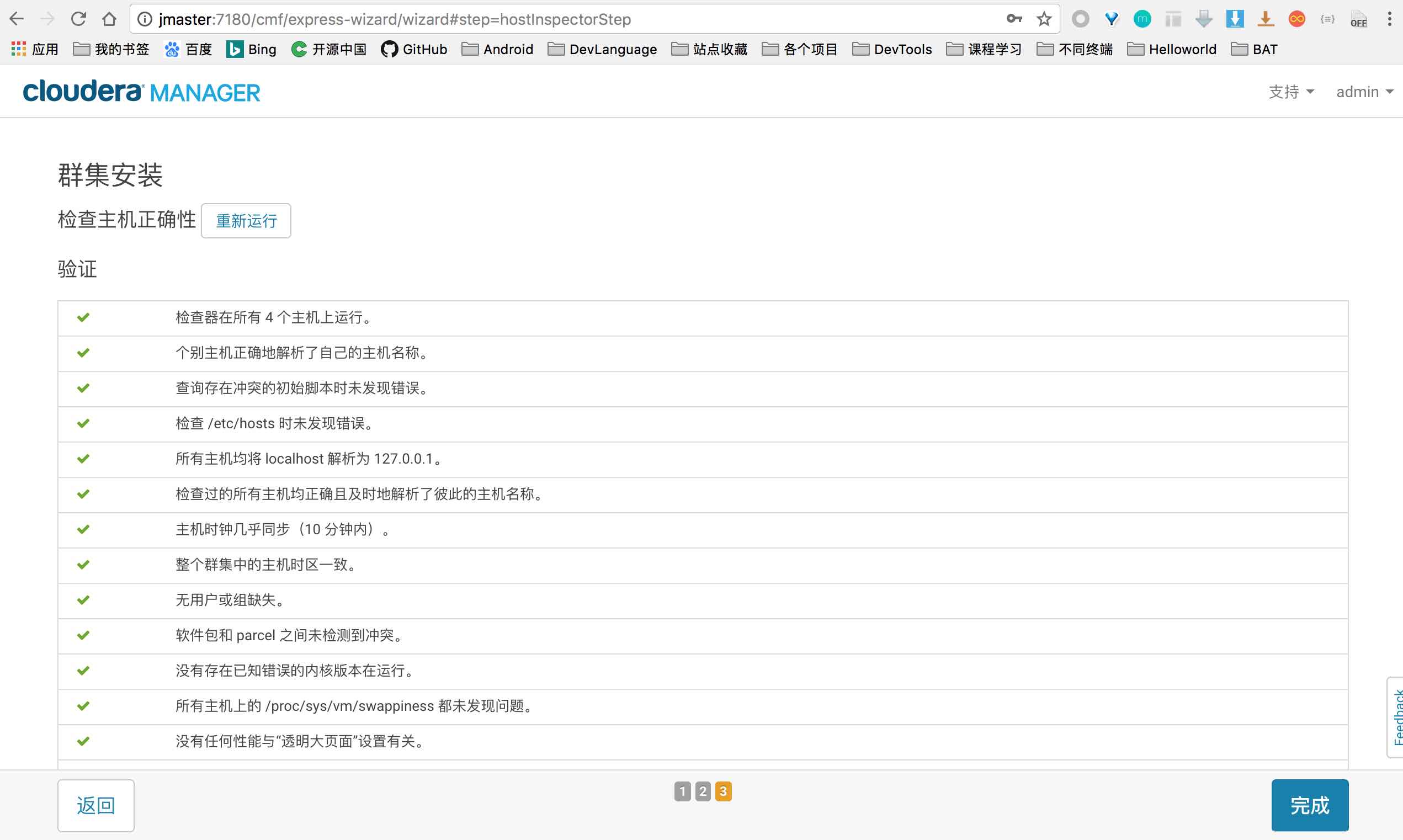
检测安装环境
这里出现下面警告,通过在所有主机上执行 echo 10 > /proc/sys/vm/swappiness, 然后再重新检测下环境即可

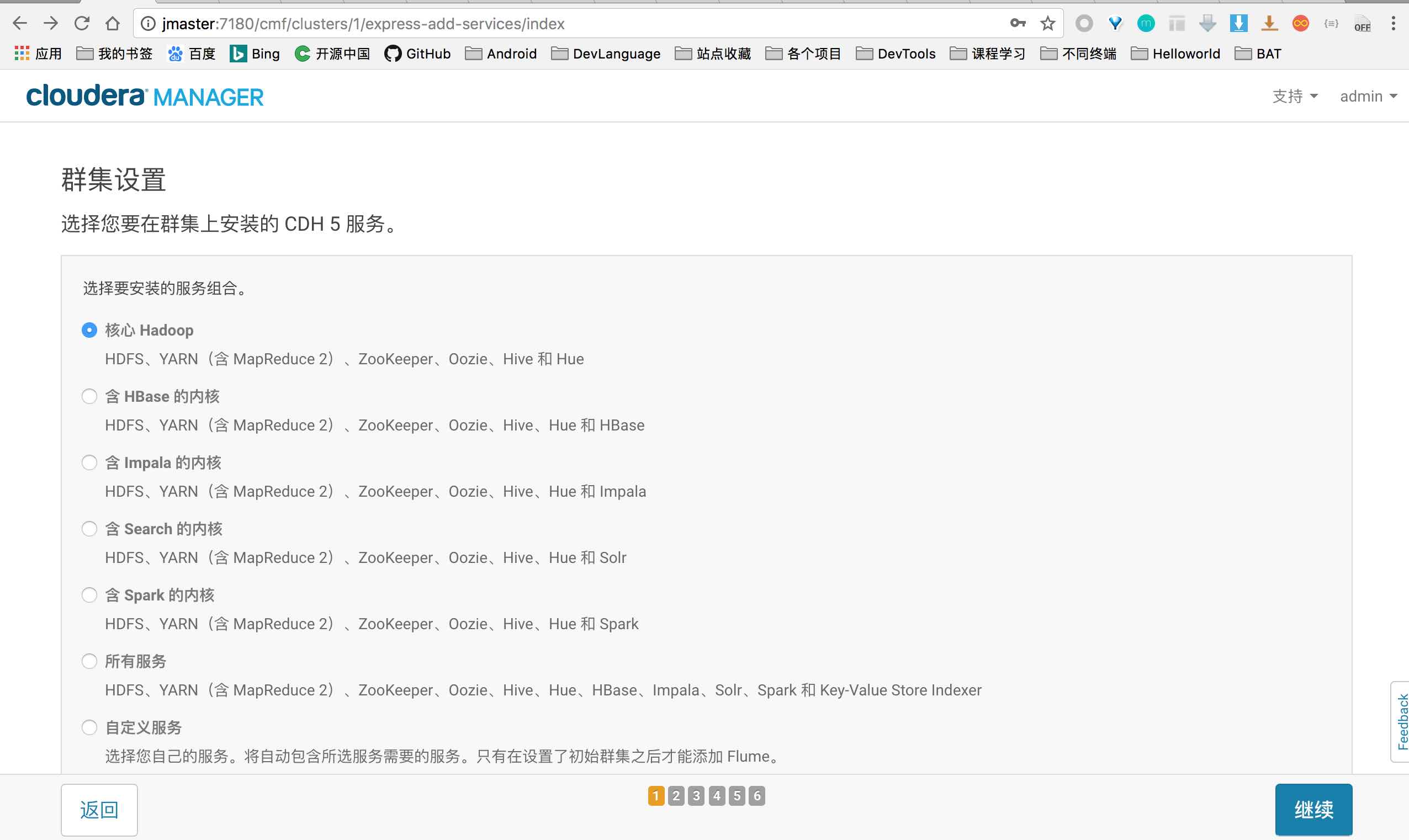
选择安装服务
这里我就选择核心服务,因为后面管理界面可以任意 增加、删除 各个服务。
角色配置
这里默认即可
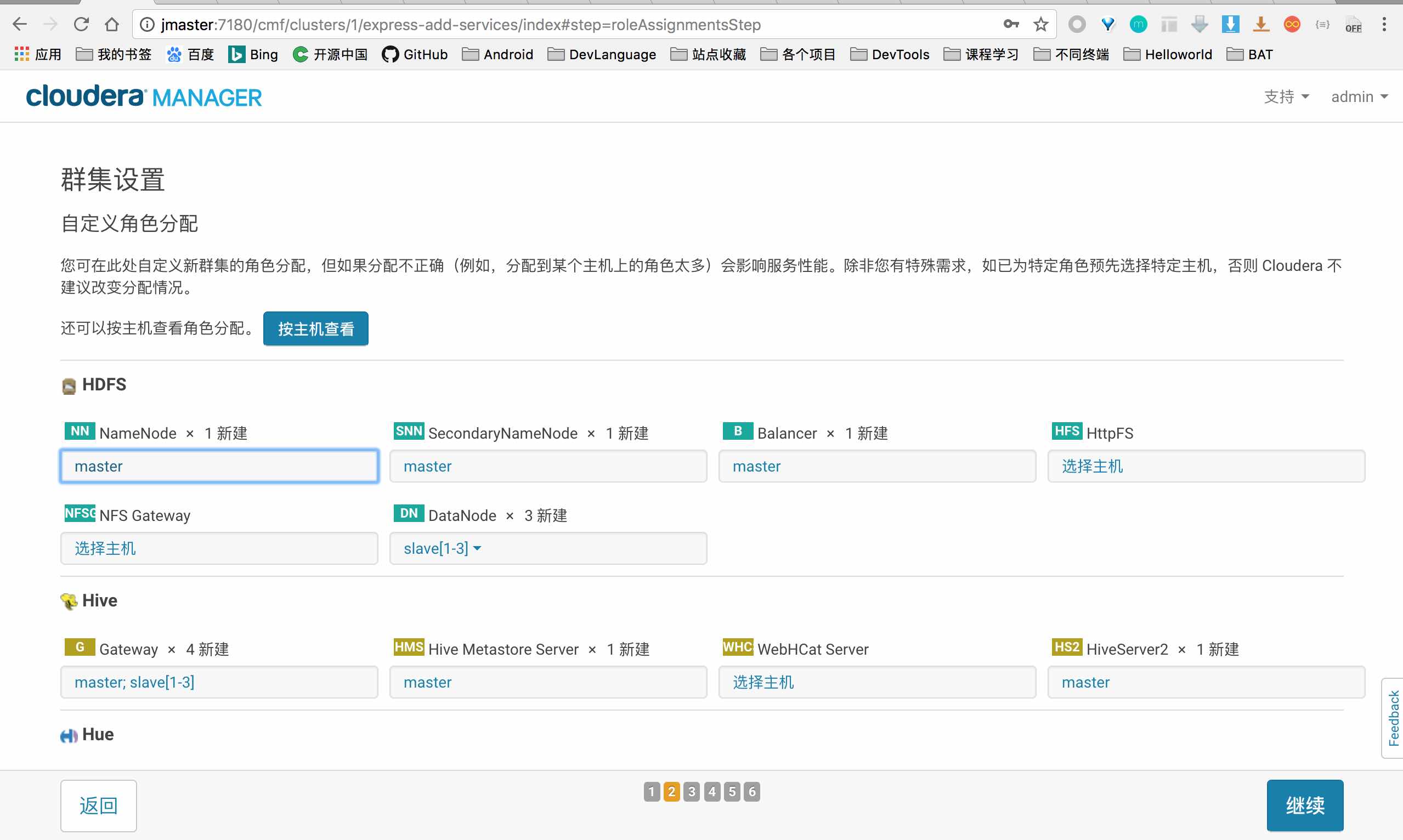
数据库配置
这里是最重要也是最容易出错的地方,配置数据库前,需要先创建数据库,我们只需要在 master 主机上创建,这里主要需要创建 四个数据库 ( hive, rman, ozzie, hue ) 和 四个用户名 ( hive, rman, ozzie, hue ).
1 | # master主机 |
此外,这里还常常出现 Hue 测试连接数据库时失败,这种情况是因为 依赖包 没有安装,这里给出我测试成功需要的依赖包,更详细的依赖包查看 官网的 Install Package Dependencies 说明:
1 | # 仅master主机 |
然后,点击 测试连接,成功后进行下一步
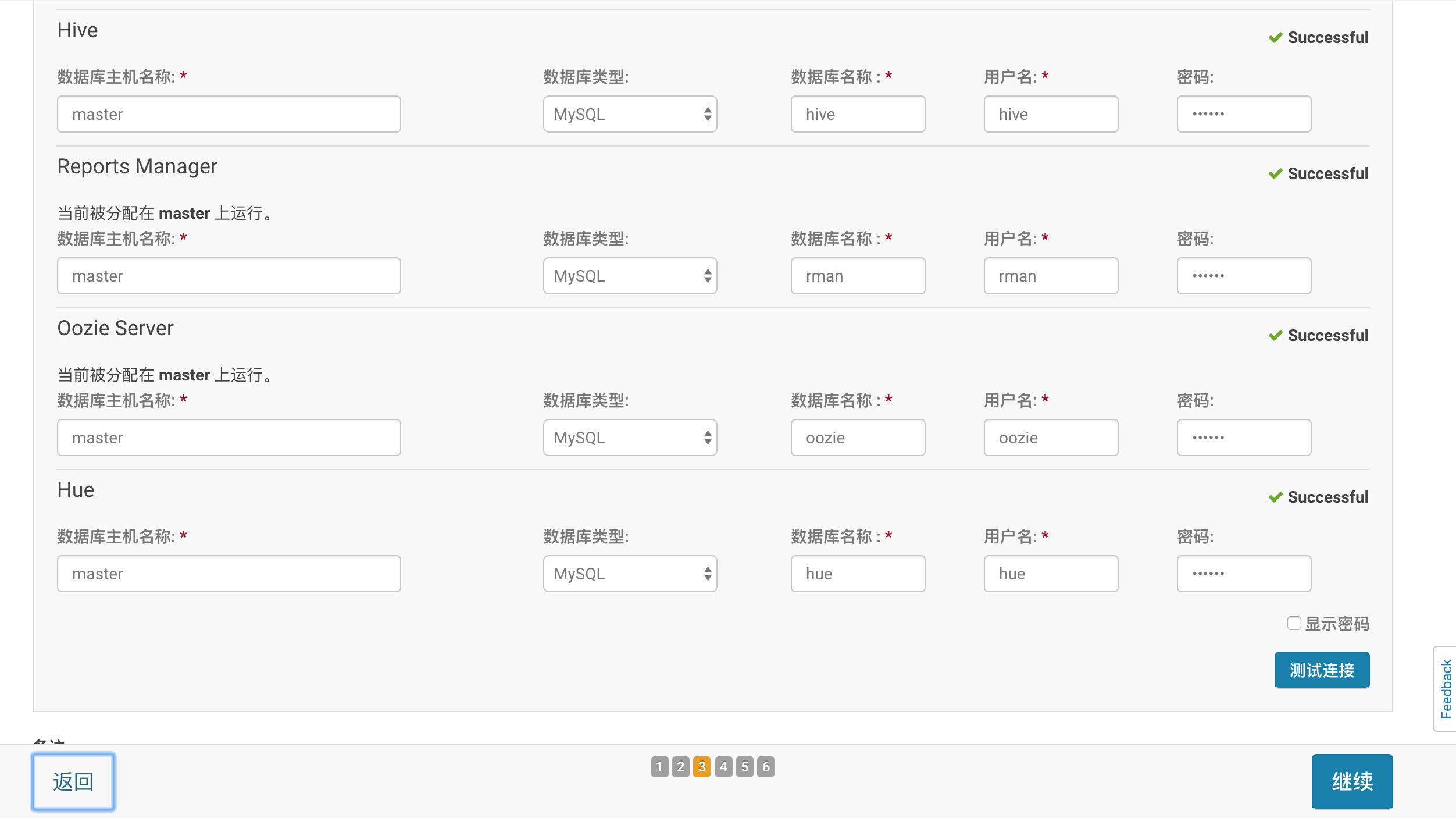
进行安装
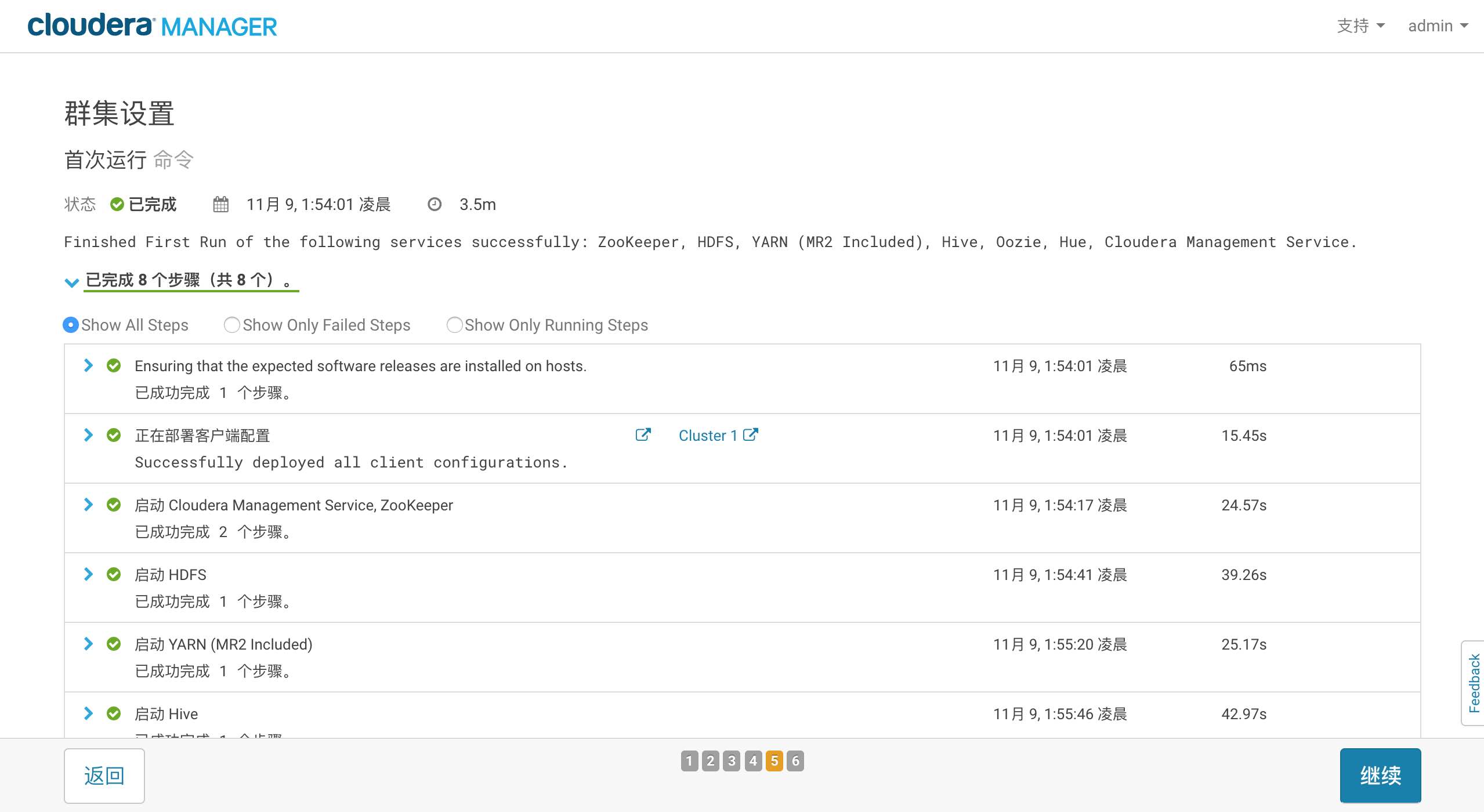
安装成功
集群界面
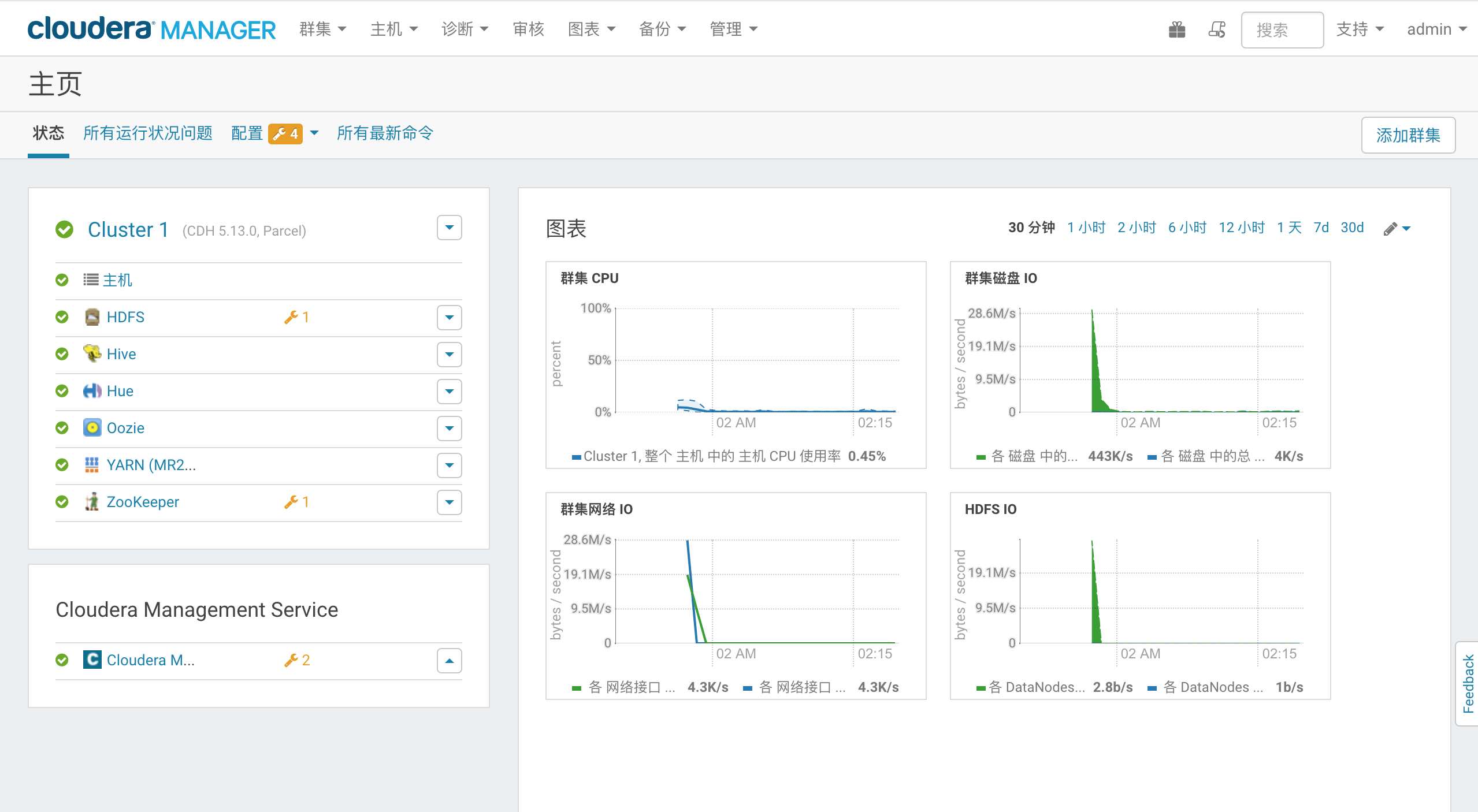
添加服务
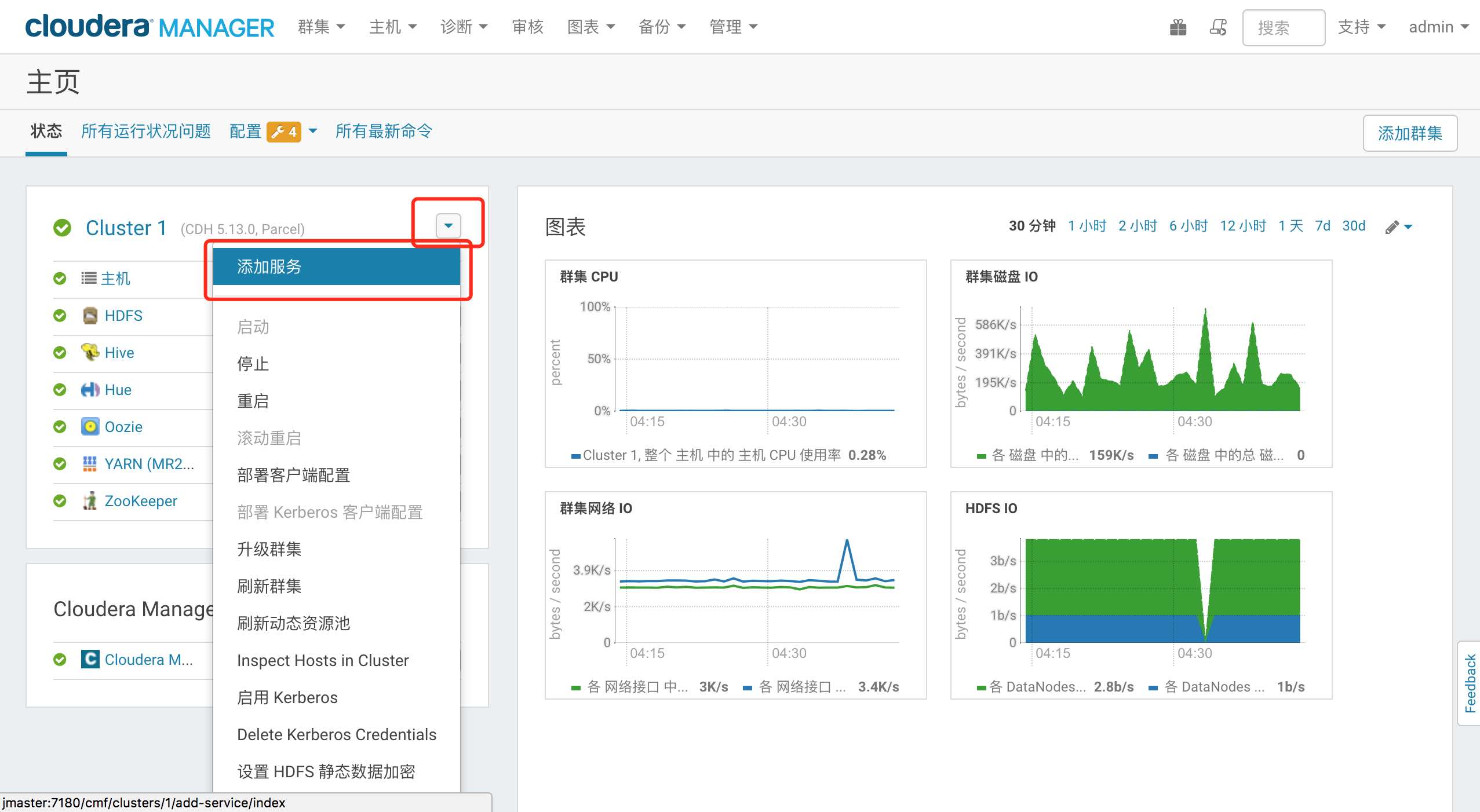
点击 集群右侧倒三角,选择添加服务
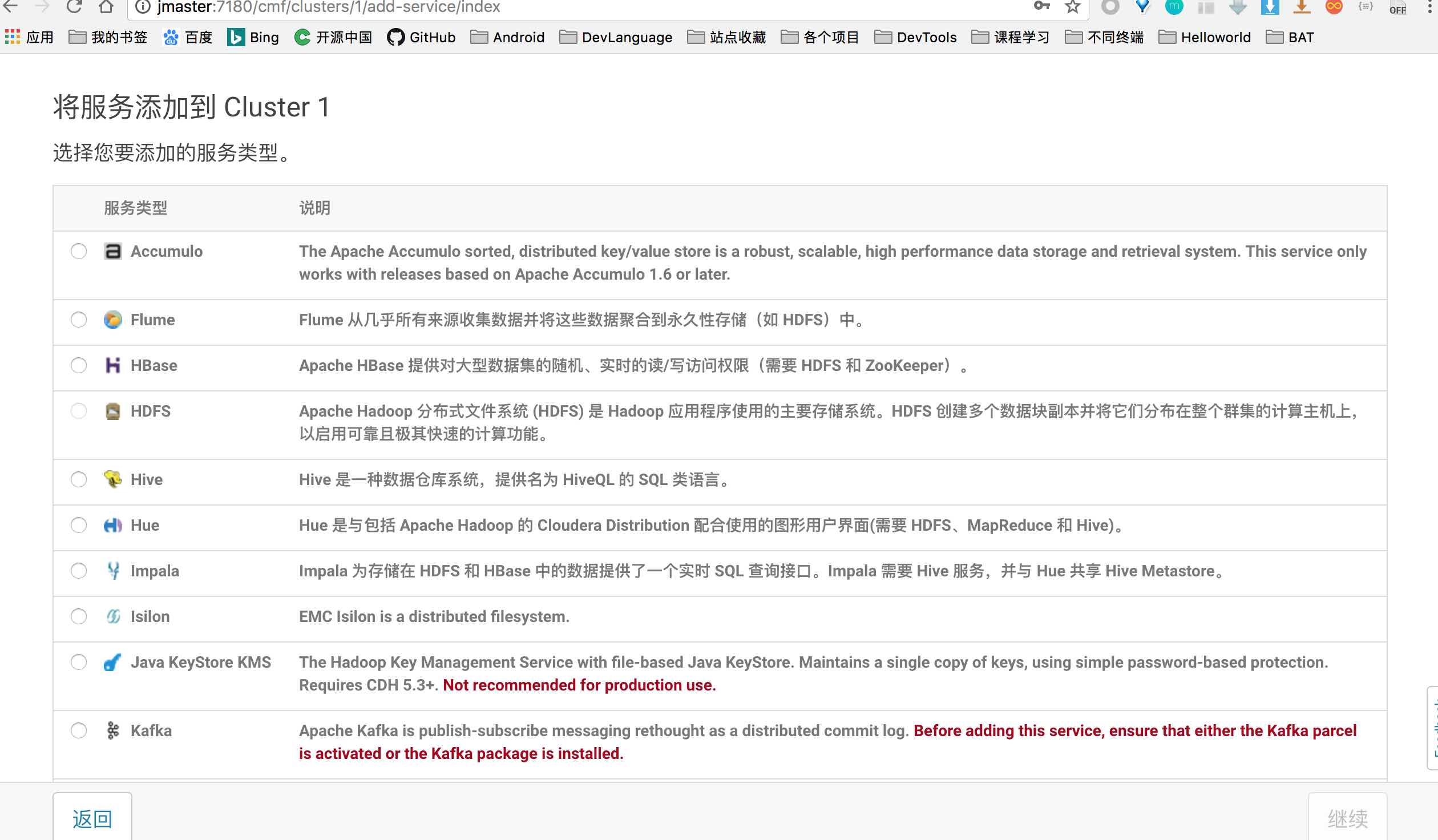
出现服务选择界面,自己根据需求选择 Hadoop 生态中的应用:
添加主机到集群
点击菜单栏上的 主机–所有主机
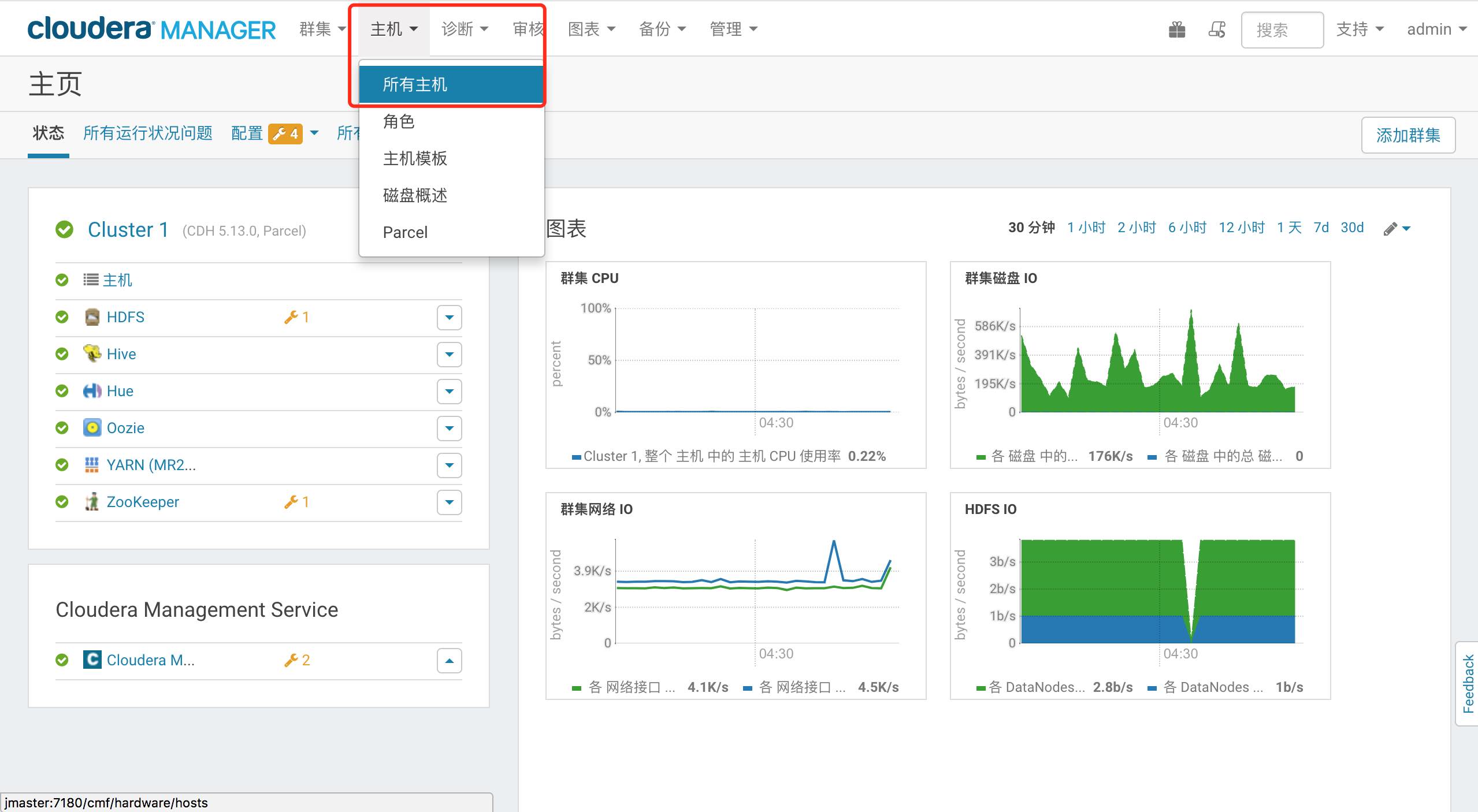
会看到当前集群的所有主机列表,点击右上角的 向集群添加新主机
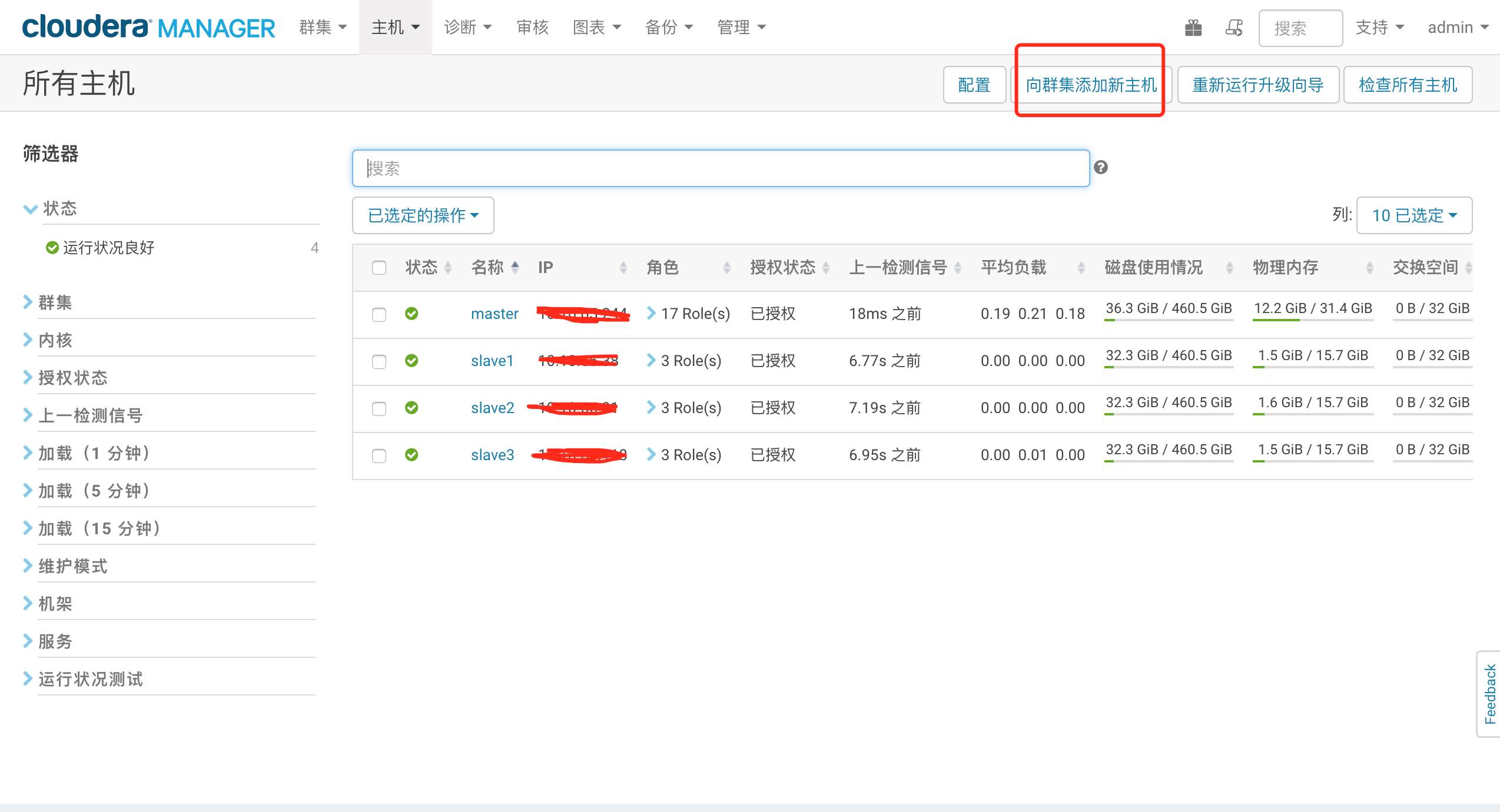
进入添加主机流程,大家一步一步下一步安装即可